Scores Description¶
This page describes the scores, that have already been implemented in the core of BigARTM library. Detailed description of parameters of the scores in the Python API can be seen in Scores, and their return values in Score Tracker.
Examples of the usage of the scores can be found in Python Tutorial and in Python Guide.
Perplexity¶
- Description:
The formula of perplexity: 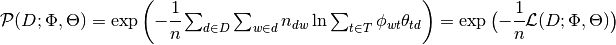 ,
,
where 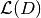 is a log-likelyhood of model parameters on documents set
is a log-likelyhood of model parameters on documents set 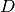 .
.
- Usage:
This is one of the main scores as it indicates the level and speed of convergence of the model. Some notes:
- smaller perplexity value means better convergenced model and can be used for comparison in case of dense models with the same set of topics, dictionaries and train documents.
- sparse model provides a lot of zero
. There’re two replacement strategies to avoid it: document unigram model (
) and collection unigram model (
). First onr is simplier but it is not correct. Collection unigram model is a better approximation, that allows perplexity comparison of sparse models (in case of equal sets of topics, dictionaries and train documents). This mode is default for score in the library, though it requires BigARTM collection dictionary.
- perplexity can be computeted on both train and test sets of documents, though experiments showed a large correlation of the results, so you may only use train perplexity as a convergence measure.
Sparsity Phi¶
- Description:
Computes the ratio of elements of 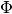 matrix (or it’s part) that are less than given
matrix (or it’s part) that are less than given eps threshold.
- Usage:
One of the goals of regularization is to achive a sparse structure of matrix using different sparsing regularizers. This scores allows to control this process. While using different regularization stratgies in different parts of model you can create a score per each part and one for whole model to have detailed and whole values.
Sparsity Theta¶
- Description:
Computes the ratio of elements of 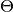 matrix (or it’s part) that are less than given
matrix (or it’s part) that are less than given eps threshold.
- Usage:
One of the goals of regularization is to achive a sparse structure of matrix using different sparsing regularizers. This scores allows to control this process. While using different regularization stratgies in different parts of you can create a score per each part and one for whole matrix to have detailed and whole values.
Top Tokens¶
- Description:
Return k (= requested number of top tokens) most probable tokens in each requested topic. If the number of tokens with 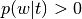 in topic is less than
in topic is less than k then only these tokens will be returned. Also the score can compute the coherence of top tokens in the topic using coocurancy dictionary (see 6. Tokens Coocurancy and Coherence Coumputation for detailes of usage from Python).
The coherence formula for topic is defined as
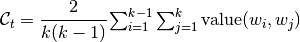 ,
,
where value is some pairwise information about tokens in collection dictionary, which is provided by user according to his goals.
- Usage:
Checking top tokens is one of the main ways of topic quality verification. But in practice the interpretation of top tokens not always correlated with the real sence of topic and it is useful to check the documents assigned to it.
Coherence is one of the best measures for automatic inpretability checking. Note, that different types of value will lead to different types of coherence.
Topic Kernel Scores¶
- Description:
This score was created as one more way to control the inpretability of the topics. Let’s define the topic kernel as  , and determine several measures, based on it:
, and determine several measures, based on it:
- the purity of the topic (higher values corresponds better topics);
- contrast of the topic (higher values corresponds better topics);
- size of the topic kernel (approximately optimal value is
).
The score computes all measures for requested topics and their average values.
Also it can compute coherence topic kernels. The coherence formula is the same as for Top Tokens score. k parameter will be equal to kernel size for given topic.
- Usage:
Average purity and contrast can be used as a measure of topics inpretability and difference. threahold parameter is recommended to be set to 0.5 and higher, it should be set once and fixed.
Topic Mass¶
- Description:
Computes the 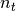 values for each requested topic in matrix.
values for each requested topic in matrix.
- Usage:
Can be useful in external (self written in Python) scores and regularizers, that requires . Much more faster than extraction and normalization.
Class Presicion¶
ToDo(sashafrey)
Background Tokens Ratio¶
- Description:
Computes KL-divergence between 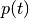 and
and 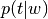 distributions
distributions 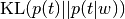 (or via versa) for each token and counts the part of tokens that have this value greater than given
(or via versa) for each token and counts the part of tokens that have this value greater than given delta. Such tokens are considered to be background ones. Also returns all these tokens, if it was requested.
Items Processed (technical)¶
- Description:
Computes the number of documents, that was used for model training since the score was included into it. During iterations one real document can be counted more than once.