BigARTM as a Service¶
The following diagram shows a suggested topology for a query service that involve topic modelling on Big Data.
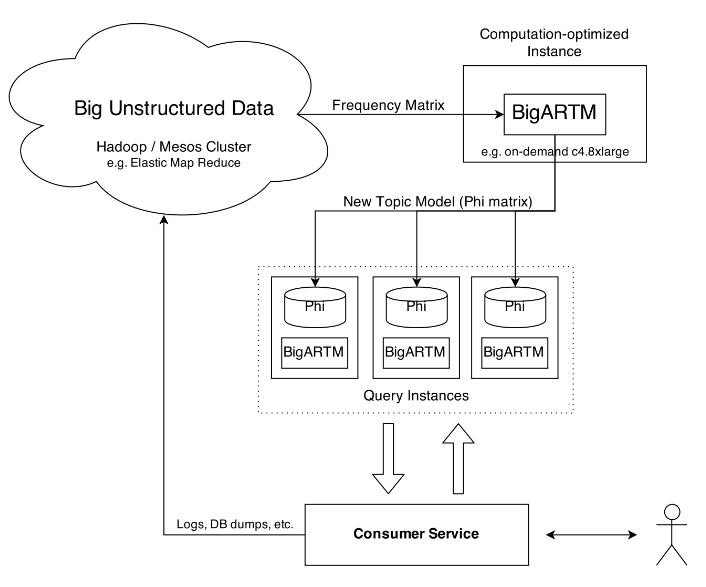
Here the main use for Hadoop / MapReduce is to process your Big Unstructured Data into a compact bag-of-words representation. Due to out-of-core design and extreme performance BigARTM will be able to handle this data on a single compute-optimized node. The resulting topic model should be replicated on all query instances that serve user requests.
To avoid query-time dependency on BigARTM component you may want to infer topic distributions theta_{td} for new documents in your code.
This can be done as follows. Start from uniform topic assigment theta_{td} = 1 / |T| and update it in the following loop:
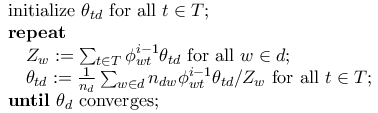
where n_dw is the number of word w occurences in document d, phi_wt is an element of the Phi matrix.
In BigARTM the loop is repeated ModelConfig.inner_iterations_count times (defaulst to 10).
To precisely replicate BigARTM behavior one needs to account for class weights and include regularizers.
Please contact us if you need more details.